
Samhita Alla
Bring ML Close to Data Using Feast and Flyte

This blog is with reference to a talk titled “Self-serve Feature Engineering Platform Using Flyte and Feast”, which was presented by Ketan Umare and Felix Wang at OSPOCon 2021, Seattle.
Feature engineering is one of the greatest challenges in applied machine learning. It is the process of transforming raw data into features that better represent the underlying problem, resulting in improved model accuracy on unseen data. When machine learning models are deployed to production, effectively operationalizing data for model training and online inference is critical. For example, building feature pipelines is one of the most time-consuming activities in ML, but also one of the most important.
There are many different challenges around operationalizing data for machine learning:
- Building feature pipelines is hard!
- Each individual project often requires the development of unique pipelines, which adds up to a lot of work.
- Data can come from many sources: data lakes, data warehouses, stream sources.
- We are often bound by performance requirements for our use case, so we have to do a bunch of extra optimizations to meet those requirements.
- Consistent data access
- Redevelopment of pipelines leads to inconsistencies in data
- Training-serving skew degrades the model performance
- Models need a point-in-time correct view of data to avoid label leakage
- Duplication of effort
- Siloed development leads to no means of collaboration
- Lack of governance and standardization
Increasingly data science and data engineering teams are turning towards feature stores to manage the data sets and data pipelines needed to productionize their ML applications[1]. Feast is one such feature store that can act as a storage and serving layer to manage your features. It is typically placed after the transformation/data pipeline that produces the feature values.
Let’s now look at how Feast can help us solve the challenges mentioned above.
- Building feature pipelines is hard!
- Feast supports easy feature creation
- Every time we query for the on-demand feature view, Feast will automatically execute the transform we specified
- Consistent data access
- Feast provides a unified serving layer through which to retrieve features, which ensures that data is accessed consistently across the offline and online use cases
- Duplication of effort
- Feast supports cataloging and discovery
- Provides a standard interface through which teams can write and publish features
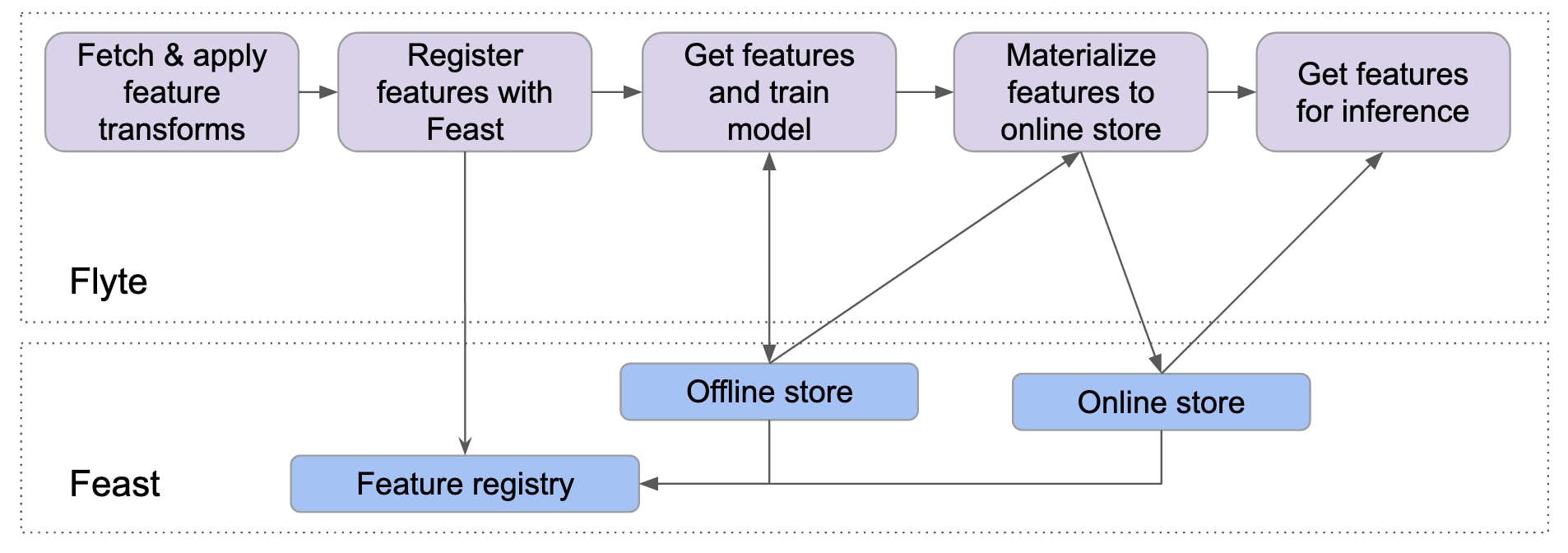
Flyte meets Feast!
Flyte provides a way to train models and perform feature engineering as a single pipeline. But it provides no way to serve these features to production when the model matures and is ready to be served in production.
This is where Feast comes into the picture.
Feast provides the feature registry, an online feature serving system, and Flyte can engineer the features. Flyte can also help ensure incremental development of features and enables us to turn on the sync to online stores only when we are confident about the features.
With Feast and Flyte, we can assert control over our features! The following are advantages we can claim with Feast in Flyte:
- Reduce skew between offline and online features -> improved model accuracy
- Simple retrieval of features -> lesser effort in managing data
- Consistent data access -> consistent data pipelines
- No more duplication of effort -> increased focus on the actual business logic
- Feature cataloging and discovery -> bridging siloed development
-> : leads to
Integration
TL;DR: Refer to the fully working example in the docs.
The goal is to train a model on the horse colic dataset to determine if a lesion is surgical or not. We first retrieve the SQLite dataset, perform mean-median imputation, build a feature store, store and load offline features, perform univariate selection, train a Naive Bayes model, store online features, retrieve random online data point, and finally, generate prediction against the data point.
When Flyte and Feast are utilized together to implement the integration, Flyte turns the feature engineering pipeline into a reproducible workflow and Feast retrieves features for training the model and online inference.
Next Steps
Feast uses a centralized registry to handle features and their metadata. In such a case, concurrent writes by the Flyte workflows to the registry aren’t allowed as it mutates the same registry. This is an anti-pattern as this impedes Flyte’s memoization.
To resolve this issue, we could make the Feast registry (R) immutable and have every application result in a new registry: (R’, R’’, R’’’). Users can then access the new registry from the Flyte API as the output of a specific pipeline. This may seem disadvantageous because there would be no single, centralized registry. On the flip side, an immutable registry supports independent feature generation.


