
Vijay Saravana Jaishanker
Flyte Map Tasks: A Simpler Alternative to Apache Spark

By Vijay Saravana Jaishanker, Alex Bain and Varsha Parthasarathy
Vijay Saravana Jaishanker is an intern at Woven Planet in the Machine Learning Frameworks Team. Vijay and his colleagues Alex Bain, Alex Pozimenko and Varsha Parthasarathy are helping to build the safest mobility in the world. A subsidiary of Toyota, Woven Planet innovates and invests in new technologies, software and business models that transform how we live, work and move. With a focus on automated driving, robotics and more, Woven Planet builds on Toyota's legacy of trust to deliver secure, connected, reliable and sustainable mobility solutions for all.
In this article, you will gain an understanding of the fundamental concepts and limitations of Apache Spark and Flyte map tasks. You will learn when and how to replace Spark tasks with Flyte map tasks.
Introduction
Apache Spark is an open-source distributed system for large-scale data processing. Spark has become a standard platform for data scientists and machine learning practitioners and is especially useful for processing huge amounts of data in parallel.
Flyte is a cloud-native distributed processing platform that lets you create highly concurrent workflows that can be scaled and maintained for machine learning and data processing. As the workflow orchestration engine for MLOps, Flyte includes a native Spark integration called the Flyte-Spark plugin. The plugin makes it especially easy to execute Spark tasks in a cloud Kubernetes cluster as part of your Flyte workflow.
A feature of Flyte called map tasks can be employed in place of Spark tasks for certain use cases. This article discusses the similarities and differences between Spark and Flyte map tasks as well as how and why Woven Planet migrated some of its Spark tasks to Flyte map tasks.
Apache Spark
The goal of Spark is to be simpler, faster and easier to use than existing distributed processing frameworks like Apache Hadoop and Apache Hive. It uses ideas from Map Reduce to make data processing more fault tolerant and embarrassingly parallel. It does this by partitioning the data and processing partitions on multiple executor cores (often across many nodes) in parallel.
One of Spark's biggest innovations is support for in-memory storage of intermediate results instead of writing to a DFS (distributed file system), which is an expensive disk and network I/O operation. Spark supports various workloads such as ETL, machine learning, Spark SQL and stream processing.
Spark architecture
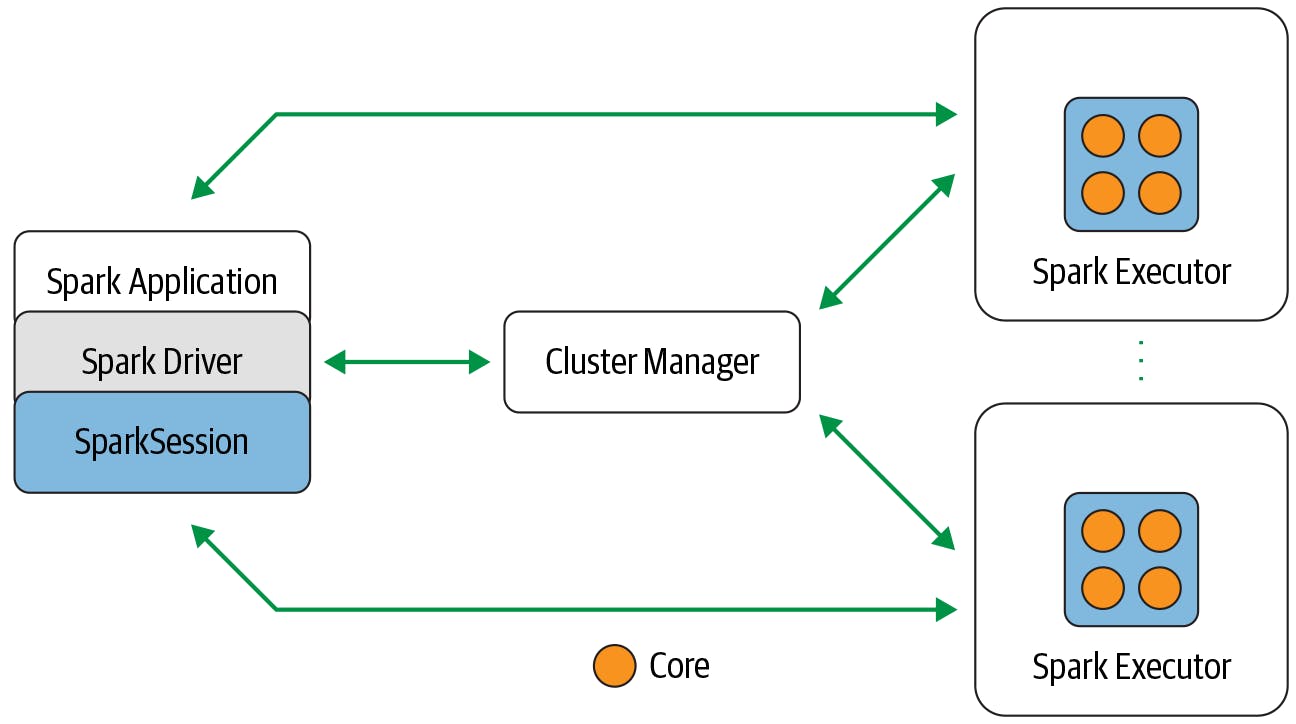
Diagram Credits: Learning Spark, 2nd Edition, by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Copyright 2020 Databricks, Inc., 978-1-492-05004-9.
Overview
Spark applications (which we refer to as "Spark tasks" in this article) begin with a driver program that is responsible for orchestrating parallel operations on the Spark cluster. The driver accesses the distributed components in the cluster (the Spark executors and cluster manager) through a SparkSession. The cluster manager (such as a Kubernetes master) is responsible for managing and allocating resources for the cluster nodes on which the Spark application runs. When run in a Kubernetes cluster, each Spark executor runs within its own Kubernetes pod and can have multiple cores (each capable of running a single unit of execution in parallel) (ref).
RDDs
Resilient Distributed Datasets (RDDs) are immutable partitioned collections of objects. They provide an abstraction for representing a dataset in distributed memory. RDDs can be loaded from many types of file systems and formats (HDFS, S3, .txt, .csv, etc.). RDDs are the building blocks of Spark data processing and fault tolerance. RDDs are built from coarse-grained transformations (such as map, filter and join) that apply the same operation to many data items in parallel.
RDD creation is based on the concept of data lineage, in which we simply log the transformations to be applied to the data and delay their execution until the user requests a concrete action to be performed with the dataset. To optimize data placement, users can also explicitly cache RDDs into memory and control their partitioning.
Partitioning
RDDs are distributed as partitions across the physical cluster. Each Spark executor is preferably allocated a task to read the partition closest to it in the network by observing the data locality. Caching happens in the executor to save time and repetitive work.
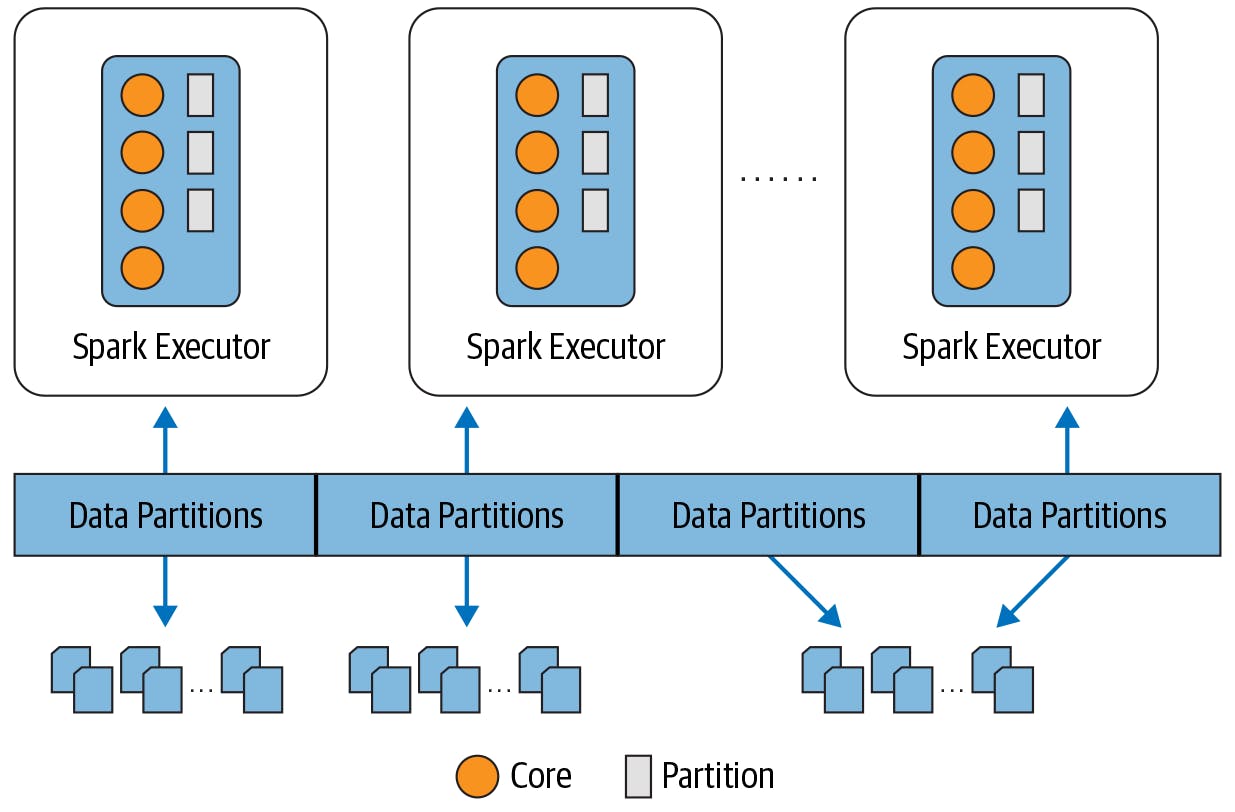
Diagram Credits: Learning Spark, 2nd Edition, by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Copyright 2020 Databricks, Inc., 978-1-492-05004-9.
Parallelism

Diagram Credits: Learning Spark, 2nd Edition, by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Copyright 2020 Databricks, Inc., 978-1-492-05004-9.
The Spark driver converts a Spark application into one or more Spark jobs , then transforms each job into a directed acyclic graph (DAG). Each node within a DAG could comprise one or more Spark stages that may depend on each other. A single unit of work or execution that will be sent to a Spark executor is called a task. Each task maps to a single core and works on a single partition of data. An executor with 16 cores can have 16 or more tasks working on 16 or more partitions in parallel, making the execution of Spark tasks exceedingly parallel!
Problems with Spark
Although Spark does a good job of being embarrassingly parallel, it can be hard to use effectively. At Woven Planet, we have seen that our users consistently run into trouble with the following issues:
- Executor cloud logs ordering: When using cloud logging (such as AWS CloudWatch logs or Google Cloud Logging), logs from all of the Spark executors are often combined in the log stream. In addition, the logs are often cluttered with messages from Spark itself. These two factors can make Spark logs hard to read and to use for debugging problems.
- Non-intuitive code: Spark-based applications are hard to debug without in-depth knowledge about Spark, especially an understanding of the various Spark configuration parameters (for the Spark driver and executors). It is very difficult for users to understand which configuration parameters need to be set and how to set them.
- Slow and inefficient failure recovery: In the case of an RDD processing failure, Spark recomputes the entire RDD lineage from its previous checkpoint. This can be extremely time consuming and compute intensive (and difficult for users to understand).
All these challenges combined can make it very difficult for users to understand and debug issues with their Spark tasks when things start going wrong.
Flyte
Flyte's map tasks feature can replace Spark tasks for certain use cases. Before we dive into map tasks, we should talk about Flyte!
Overview
Flyte is an open-source distributed processing platform intended to run in a Kubernetes cluster. At its heart, Flyte is a task and workflow orchestration and execution platform. Similar to previous open-source workflow systems (such as Apache Airflow), the fundamental capability of Flyte is to make it easy for you to write, manage and execute large-scale data processing workflows. The difference with Flyte is that it was written from the ground up to operate in a fully containerized and cloud-native environment and to be run in the cloud at massive scale. At Woven Planet, we execute thousands of Flyte tasks daily in our AWS cloud Kubernetes clusters.
Flyte concepts
The core concepts of Flyte are tasks and workflows. A task represents an independent unit of execution with typed, declarative inputs and outputs. A very simple example of a Flyte task is a Python function with typed inputs and outputs (you just add the <span class="code-inline">flytekit.task</span> annotation to your Python function to declare it as a Flyte task).
Simple example of a Flyte Python task
In addition to Python tasks, Flyte provides a plugin system that enables users to define custom task types (such as the Spark tasks and map tasks that are the subject of this article). Users have contributed many different task type plugins in order to provide integrations between Flyte and other systems (check the Flyte website for more information).
A Flyte workflow is a DAG of tasks. Workflows combine tasks so that inputs and outputs flow from one task to the next in the correct dependency order. Workflows and tasks can be written in any language, although Python is the best supported at the moment.
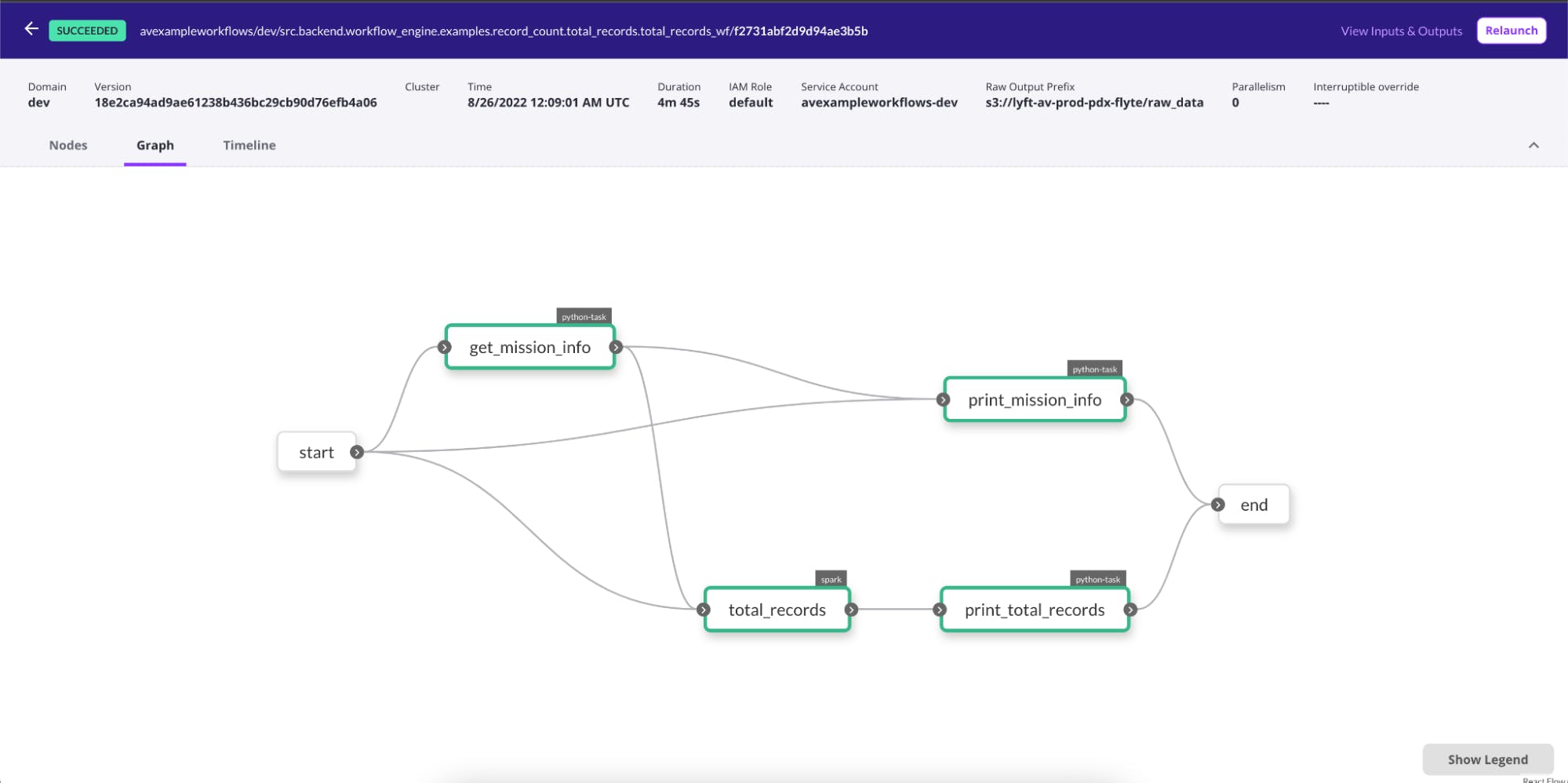
Example of a Flyte workflow with four tasks. The <span class="code-inline">get_mission_info</span> task must run first since its outputs flow into the <span class="code-inline">total_records</span> and <span class="code-inline">print_mission_info</span> tasks.
Flyte map tasks
Map tasks are less powerful than Spark tasks, but they are much easier for users to understand and debug. In the rest of this article, we discuss when to use map tasks and how to use them effectively.
The simple map-reduce pattern
Flyte map tasks can specifically replace Spark tasks for simple map-reduce parallel data processing patterns. This is a pattern with the following characteristics:
- The data can be represented as a list of inputs with the intention that each input can be processed independently and in parallel. We refer to this as the "map" operation. The level of parallelism in this stage might be very large — for example, processing hundreds or thousands of inputs in parallel.
- The outputs from processing each input can all be sent to a single task that is responsible for processing them into a final output. We refer to this as the "reduce" operation.
You might already know that with Hadoop and Spark, the map operation produces key-value pairs that are combined, shuffled, sorted and processed with many reducers. In the simple map-reduce pattern supported by Flyte map tasks, we simply process each input separately and send all the resulting outputs to a single task for final processing.
Fixing problems with Spark
Earlier in the article, we discussed a few problems with Spark that can make it very difficult for users to understand and debug issues with their Spark tasks. Flyte maps are much more user-friendly for the following reasons:
- Each map task input is processed with a separate container that has its own logs link from the Flyte web interface.
- There are no more Spark configuration parameters to set or complicated Spark RDD transformations to learn. Flyte map tasks just run the Python code for your map operation.
- Flyte map tasks support failure retries. Failures and retries are presented in the Flyte web interface in a simple and clear manner.
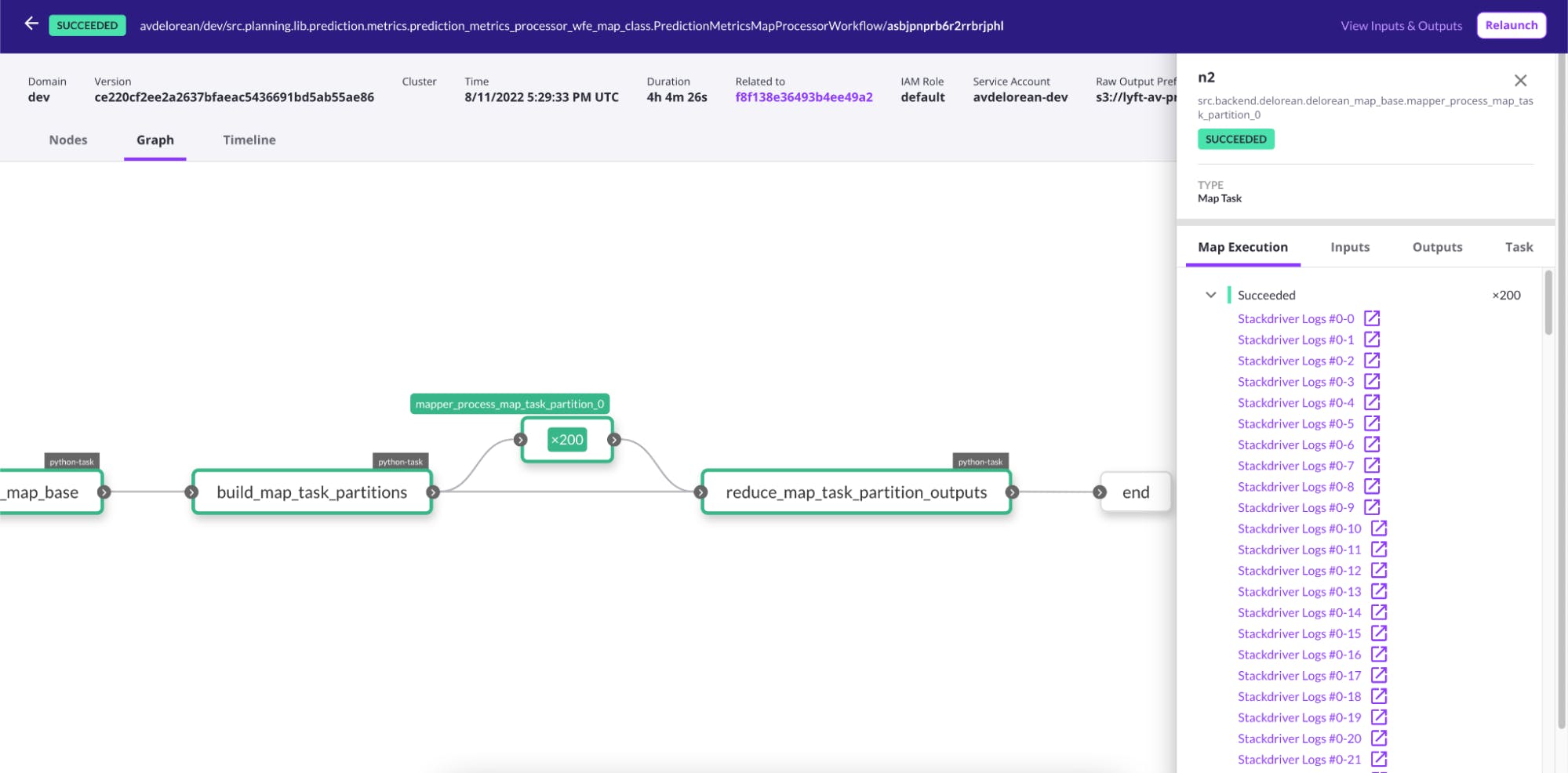
Flyte map task processing 200 inputs (with separate container log links for each)
When to use Flyte map tasks
At Woven Planet, we have been surprised at how often we use Spark for the simple map-reduce pattern. It turns out that nearly all of our workflows that process machine learning data for computer vision fit this pattern and can benefit from being converted to use Flyte map tasks.
For example, one of our largest Spark workflows involves processing images collected by our fleet of self-driving test vehicles. The Spark task in the workflow loads collections of images in parallel and applies an ML model to each image that detects objects of interest in the image. For this "offline detection" workflow, we do not actually use any advanced features of Spark (such as RDD caching or join operations).
We replaced Spark in this workflow with Flyte map tasks that make all the detections using hundreds of containers in parallel (that run the user-defined map operation). After making this switch, users remarked to us how much easier it is to understand and maintain the Flyte map task version of the workflow.
When not to use Flyte map tasks
We have some Spark tasks that actually do require Spark SQL, RDD caching or distributed join operations. These tasks do not fit into the simple map-reduce pattern, and we plan to keep using Spark for them.
Spark to Flyte map task
In this section, we will explain how to convert a Spark task into a Flyte map task.
Spark task in Flyte
In order to declare a Spark task with Flyte, add the <span class="code-inline">flytekit.task</span> annotation to a Python function and declare the spark_conf dictionary parameter (that holds the Spark configuration parameters). This enables you to retrieve a SparkSession object from Flyte that you can use to build a Spark RDD or Spark DataFrame (or to make other Spark API calls).
The example below is a (greatly simplified) version of our offline detection Spark task. The task builds an RDD of the image paths on which we want to run detection and uses 100 Spark executors to process all the image batches in parallel. Our actual production Spark task for this is quite a bit more complicated, but it builds on the same basic idea.
A simplified example of our Flyte Spark task for offline image detection
Convert to Flyte map task
Now we will convert this example Spark task into a Flyte map task workflow that fits the simple map-reduce pattern. If you remember, the simple map-reduce pattern requires us to declare a Flyte task to process each input and a task to reduce the outputs into a final output.
Step 1: Declare a task that maps each input to an output and another task to reduce all map outputs to a final output. You can optionally specify task resource limits and retries.
We also need to split out the code that scans all the images from S3 into its own Flyte task. This task returns a Python List type (since Flyte map tasks must process a list).
Step 2: Split out the code the builds the list of inputs into its own task
Flyte map tasks can only be invoked from within a Flyte workflow. As the final step, add all three tasks to a Flyte workflow and use <span class="code-inline">flytekit.map_task</span> to tell Flyte which task to use for the map operation.
Step 3: Declare a Flyte workflow that uses <span class="code-inline">flytekit.map_task</span> with your map function and then pass all the results to your reducer function.
That is all that is necessary to replace the Spark task with an equivalent Flyte map task workflow. The magic part of this is that Flyte will automatically scale the map task according to the number of inputs (e.g. the size of the <span class="code-inline">image_batches</span> list in the example above). If you have enough cluster resources, you can easily run map tasks that process hundreds or thousands of input elements in parallel.
There are also simple keyword parameters that can be passed to the <span class="code-inline">flytekit.map_task</span> function to control the maximum degree of parallelism (if you need to be careful not to overwhelm your cluster).
Map task performance compared to Spark
We have run quite a few experiments using both Flyte map tasks and Apache Spark. Spark performance can vary widely depending on your exact Spark program, configuration and RDD partitioning. It is difficult to make a truly apples-to-apples comparison. We have settled on a couple of common-sense performance guidelines:
- If you run a Flyte map task to process K inputs in parallel and an equivalent Spark program that uses K executors to process the data, both will take roughly the same amount of time, except that there seems to be about 10% extra overhead with Flyte when processing each input. We had some discussions about this with the open-source Flyte community, and work is being done to reduce this overhead. We have found the community to be friendly, helpful and welcoming of contributions (especially to improve map tasks)!
- If you run a complex data processing job with many transformations, you should definitely use Spark as it is optimized for such use cases. However, for data processing jobs that fit the simple map-reduce pattern, the convenience and usability of Flyte map tasks is absolutely worth the small amount of extra overhead they add to such jobs.
Summary
Flyte map tasks are a simple alternative to Spark tasks that fit the simple map-reduce pattern. At Woven Planet, we have found that we can use map tasks for a variety of common machine learning workflows. Users have told us that they find Flyte map tasks much easier to understand and maintain than the previous Spark tasks. However, keep in mind that Flyte map tasks cannot replace all the functionality of Apache Spark.
References: Learning Spark, Spark in Action, RDD paper, Flyte map tasks

